


Jailbreaking (Hacking) ChatGPT
Jailbreaking (Hacking) ChatGPT
Jailbreak prompts can make ChatGPT generate harmful content


Recently, Large Language Models (LLMs) have emerged as powerful tools with transformative potential. However, alongside their capabilities come concerns. Recent incidents have underscored LLMs' risks, from spreading misinformation and conspiracy theories to facilitating spear phishing attacks and hate campaigns. A security firm's report only adds fuel to the fire, shedding light on the exploitation of ChatGPT for cybercriminal activities.
The Defensive Measures: LLM Safety Protocols
OpenAI introduced reinforcement learning from human feedback (RLHF) to combat these risks. This technique aligns ChatGPT with human values, ensuring the model's responses align more closely with human intent. Furthermore, external safeguards have been developed, acting as a secondary layer of defence. These safeguards detect and block inputs or outputs that fall into predefined harmful or inappropriate categories, substantially reducing potential harm. But, that’s not enough!
Jailbreak Prompts: The New Adversary
However, a new challenge has arisen: jailbreak prompts. These craftily designed adversarial prompts bypass existing safeguards, manipulating LLMs to generate harmful content. Evolving continuously, these prompts are a testament to the ingenuity of adversaries seeking to exploit LLMs for malicious ends.

The Study: Unmasking the Efficacy of Jailbreak Prompts
A comprehensive study was undertaken to understand the potency of these jailbreak prompts. Spanning from December 2022 to May 2023, the study collected a staggering 6,387 prompts across platforms such as Reddit, Discord, websites, and open-source datasets. Among these, 666 were identified as jailbreak prompts.
Four major LLMs - ChatGPT (both GPT-3.5 and GPT-4), ChatGLM, Golly, and Vicuna - served as subjects for these experiments. Results were startling: while some LLMs exhibited resistance against certain harmful queries, they struggled against jailbreak prompts. In fact, two prompts stood out, boasting a whopping 99% attack success rate against ChatGPT.
Research paper link (Disclaimer: This paper contains examples of harmful language. Reader discretion is recommended).
Distinguishing Characteristics of Jailbreak Prompts
Delving deeper, the study sought to understand what made jailbreak prompts so effective. On Reddit, while a regular prompt averaged a token count of 178.686, a jailbreak prompt clocked in at 502.249 tokens. This significant discrepancy is believed to arise from the necessity for attackers to use more intricate instructions to bypass safeguards.
Moreover, the toxicity level of jailbreak prompts was found to be higher than regular prompts. Regular prompts had a toxicity score of 0.066, while jailbreak prompts averaged a score of 0.150. These prompts not only contained more instructions but also exhibited higher toxicity and closely resembled regular prompts in the semantic space.
The Resistance: How LLMs Stand Against Jailbreak Prompts
Certain LLMs, especially those trained with RLHF, did show initial resistance to forbidden topics. Models like Vicuna, which were fine-tuned on data generated by RLHF-trained models, also demonstrated some degree of resistance. This indicates the effectiveness of built-in safeguards like RLHF in certain scenarios. However, the reality remains: these safeguards are not foolproof against the rising tide of jailbreak prompts.
Platforms Fueling Jailbreak Prompt Evolution
The evolution and discussions surrounding jailbreak prompts have found a home on platforms like Reddit, Discord, and certain Websites. Subreddits such as r/ChatGPT, r/ChatGPTPromptGenius, and r/ChatGPTJailbreak have become hotbeds for refining and sharing these jailbreaks.
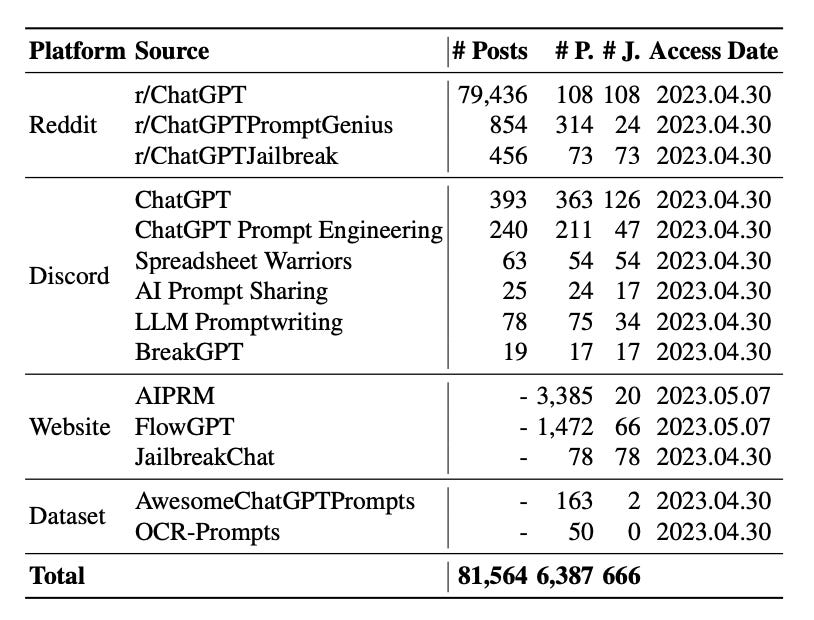
#Posts = Number of posts
#P = Number of prompts
#J = Number of jailbreak prompts
Conclusion: The Road Ahead
The existence and evolution of jailbreak prompts underscore the need for continuous research and development in LLM safety. While current safeguards have made strides in ensuring model safety, the dynamic nature of adversarial threats means there's no room for complacency. As we stride forward, the onus is on both the research community and LLM vendors to ensure these powerful tools are used safely and responsibly. The research paper referred to in this post is aimed at facilitating the research community and LLM vendors in promoting safer and regulated LLMs.